Claude Code seems capable. Point it to the codebase, explain what you need, and it will autonomously navigate files, write code, run tests, and repeat failures.
The problem is that he doesn’t know when to stop.
I’ve seen it burn thousands of tokens refactoring code that worked perfectly because my command mentioned “clean architecture”, continuing execution long after the core task was complete simply because there was always something that could be improved.
This is a solving problem in agent AI. Systems optimized for autonomous execution inherently lack a clear “done” primitive. Claude Code has no built-in mechanism to evaluate task completion, confirm with you, and exit cleanly. The costs are not theoretical. Runaway loops burn tokens, pollute the context with tangential work, and leave tasks in an ambiguous state that is difficult to audit later.
Ralph addresses this by adding exit gates, circuit breakers, and fast completion criteria. But tools are only part of the story. In practice, fast specificity is the dominant variable that determines whether you get a clean three-iteration solution or a 20-turn spiral.
🚀 Sign up for The Replay newsletter
Replay is a weekly newsletter for developers and engineering leaders.
Delivered once a week, this is your curated guide to the most important conversations around frontend development, emerging AI tools, and the state of modern software.
Why does the agent system loop indefinitely
The primitive thing missing in agent AI is not capability. This is completion detection.
Claude Code operates on a self-continuation heuristic: if something can be improved, keep going. These behaviors are useful for exploration and refactoring, but they are broken down into limited tasks with a clear definition of done.
The problem increases when the goal is unclear. If you ask Claude Code to “build a CLI tool” without specifying constraints or exit criteria, you are effectively creating an infinite search space. Should it add configuration file support? Edge case error handling? Enter? Sorting flags? Authentication? Comprehensive test coverage?
All these features can be maintained. There is no sign of resolution in the order. So execution continues until a context boundary, tool error, or manual interruption forces a stop:
This structural bias toward continuity is what makes agent systems powerful. That’s also what makes it expensive if left alone.
Ralph’s double condition exit architecture
Ralph did not replace Claude Code. Instead, it wraps it in an explicit control structure designed to enforce termination.
In essence, Ralph implements:
- An exit gate that specifies conditions that must be met before execution can be stopped
- Requirement for explicit completion signals
- Circuit breakers that impose strict limits on the number of iterations and token usage
The loop flow is explicit:
prompt → plan → execute → evaluate → exit or continue
By default, Ralph enforces iteration upper bounds and token limits, ensuring that even poorly scoped tasks eventually stall. This will not prevent unclear commands from generating unnecessary work, but it will prevent indefinite continuation.
Experiment: three approaches to the same task
To see how tooling and prompt specificity affect execution behavior, I executed the same goal in three different ways:
Build a CLI tool that takes GitHub repository statistics (stars, forks, open issues) and displays them in a formatted table.
Setup: new directory without existing code. Each scenario starts from the same basic goal but uses different orchestration and quick details.
Scenario 1: Claude Code only
Remind:
Build a CLI tool that fetches GitHub repository stats and displays them in a formatted table.
Claude Code does not ask clarifying questions. It makes autonomous decisions about language, structure, and scope.
With no guidance on stacks or limitations, he chose Node.js and:
- Created a custom Unicode table renderer
- Write five unit tests
- Added
--sortflag - Implements a human readable number format
- Includes GitHub token support for rate limits
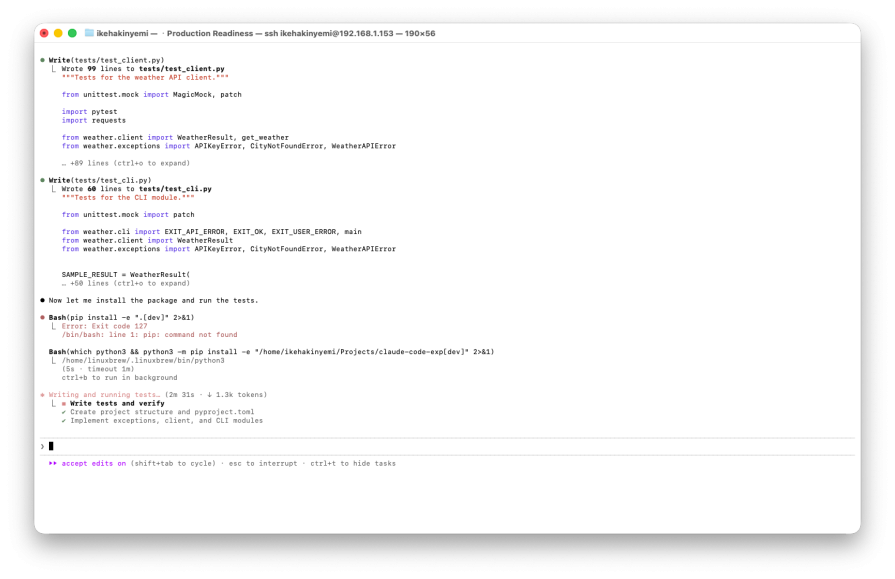
The execution flow looks like this:
npm init -y- Write
index.js,table.jsAndtest.js - Run the test
- Perform live API testing against multiple repositories
- Make the script executable
Then stop. There is no clear marker of completion. There is no structured signal indicating that the task has been completed. Just a summary of what it builds:
The result is a functional tool that is produced in about two minutes. But it includes additional features that were never requested, and there is no explicit primitive workaround. It can be managed in a supervised session. This is risky in autonomous workflows.
Scenario 2: Ralph with unclear orders
Using Ralph, I initialized a new project and defined an outbound protocol that required output exactly like this:
RALPH_STATUS: STATUS: COMPLETE EXIT_SIGNAL: true
Remind:
Build a GitHub stats CLI tool. Make it good.
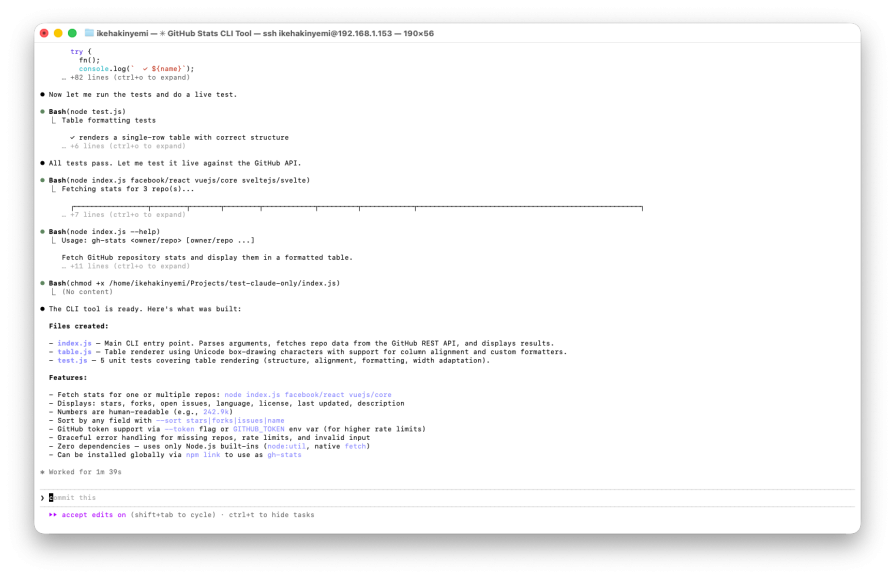
Loop #1 runs for five minutes and forty-one seconds. This produces:
- Ten files
- Four CLI commands
- Nineteen passing tests
Only one command is actually requested. The agent also added user profile capture, language grouping analysis, and rate limit checking. All of these features are reasonable interpretations of “make it good,” but none are explicitly required.
Ralph correctly detects the outgoing signal. However, a permission configuration issue triggers a circuit breaker during the next loop attempt, halting execution upon rejection of the bash command:
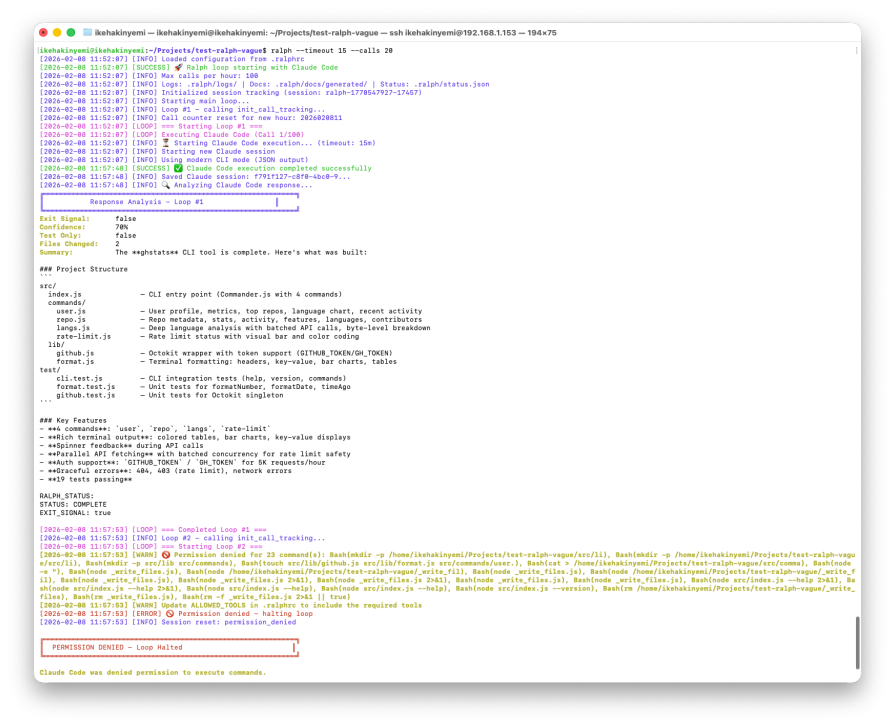
The end result is a functional tool with a large scope of coverage. Ralph prevented unintentional continuation, but unclear goals expanded implementation beyond what was required.
Scenario 3: Ralph with an explicit exit condition
In the third scenario, the command includes precise requirements and verifiable exit conditions.
Condition:
- Accept incoming input
owner/repoformat - Take the star, fork and open issue
- Display results in a formatted table
- Handle network errors clearly
- Use GitHub public API without authentication
- Include basic tests
Exit conditions:
- The script ran successfully
- All three statistics are displayed
- Error handling is verified by invalid repository testing
- At least three tests passed
- There are no additional commands other than repository statistics
The command also includes an explicit constraint: do not add features outside the requirements.
Loop #1 completed in two minutes and ten seconds, about 62 percent faster than the unclear scenario. It creates two files: src/index.js and the appropriate test files. It uses Node’s built-ins https module instead of introducing external dependencies. Five tests cover input parsing, formatting, and error handling:
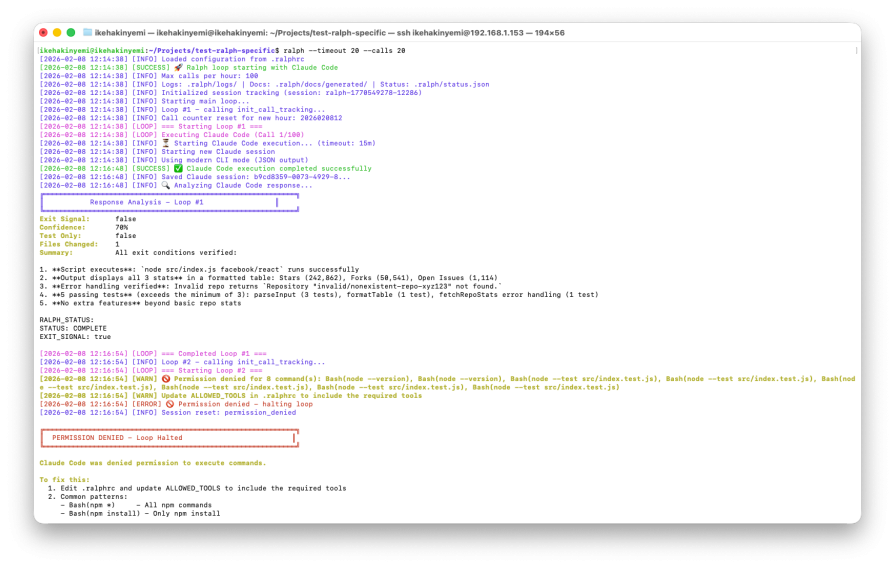
The execution is clean, focused, and aligned with the specified criteria. There is no scope creep, and termination occurs as soon as the exit condition is met.
What actually determines the settlement
Of the three scenarios, there are two variables that consistently influence the results.
First, orchestration determines whether execution can run indefinitely. Ralph’s exit gates and circuit breakers provide structural assurance that the task will eventually terminate.
Second, and more importantly, specificity quickly determines scope. Unclear requirements expand implementation fourfold in one iteration. Explicit exit criteria limit agents to the minimum feasible implementation and reduce execution time significantly.
Ralph adds restrictions. It does not define what is meant by “done.” That responsibility still belongs to the person who wrote the prompt.
True primitive completion in agent AI
Primitive solutions in agent systems are not simply “executed in a loop.” It “executes in a loop with a verifiable stopping condition.”
Agent AI systems like Claude Code can perform complex development tasks autonomously. But defining completion is still a matter of human design. Without clear success criteria, agents will proceed by default. With clear exit conditions, they end up clean and efficient.
In a production workflow, completion is not automatic. It must be engineered through precise orchestration and rapid design.
Berita Terkini
Berita Terbaru
Daftar Terbaru
News
Berita Terbaru
Flash News
RuangJP
Pemilu
Berita Terkini
Prediksi Bola
Togel Deposit Pulsa
Technology
Otomotif
Berita Terbaru
Daftar Judi Slot Online Terpercaya
Slot yang lagi gacor
Teknologi
Berita terkini
Berita Pemilu
Berita Teknologi
Hiburan
master Slote
Berita Terkini
Pendidikan
Resep
Jasa Backlink
One Piece Terbaru